DynamoDB does not support auto-incrementing IDs for items. They can be a performance bottleneck at scale, and most workloads are better off with UUIDs anyway. However, there are use cases where auto-incrementing integers are required. In this article we will use DynamoDB Transactions, Conditions, and Atomic Counters to achieve reliable auto-incrementing IDs at any scale.
The scenario
Our scenario involves users in a DynamoDB Table. There are three requirements:
- Each new user needs its own unique numeric identifier
- Those identifiers should always increase
- The identifiers should be coherent (no gaps)
An example list of users matching these criteria would look like this.
| PK | NumIdentifier | UserName |
|---|---|---|
| User#Uros | 1 | Uros |
| User#Alex | 2 | Alex |
| User#Luc | 3 | Luc |
The problem
DynamoDB offers no way to efficiently fetch the last increment ID in this table, so we add an additional item named UserMetadata. This item keeps track of the last user increment ID added to the database, like this.
| PK | NumIdentifier | UserName | LastID |
|---|---|---|---|
| UserMetadata | 3 | ||
| User#Uros | 1 | Uros | |
| User#Alex | 2 | Alex | |
| User#Luc | 3 | Luc |
If we want to add a new user, we could increment the LastID with an atomic counter like this:
client.update_item(
TableName="Users",
Key={"PK": {"S": "UserMetadata"}},
UpdateExpression="SET LastID = LastID + :incr",
ExpressionAttributeValues={
":incr": {"N": 1},
},
)This will guarantee that the LastID is increased by one, regardless of the number of concurrent operations taking place on the table. Next, we use the updated ID to add a new user:
client.put_item(
TableName="Users",
Item={
"PK": {"S": "User#Kirk"},
"NumIdentifier": {"N": next_id},
"UserName": {"S": "Kirk"},
},
ConditionExpression="attribute_not_exists(PK)",
)But if this operation fails, for example if the user Kirk already exists, the LastID value would still be incremented, and you couldn’t reliably decrement it because new users might have been added in the meantime. The problem: this implementation leads to incoherent identifiers and breaks requirement #3.
The ideal solution would be to use transactions. Unfortunately, DynamoDB Transactions don’t allow for results from one operation in the transaction to be used in another operation in the same transaction. Take a look at the transactions example from the DynamoDB Transactions release blog, for example:
client.transact_write_items(
TransactItems=[
{
"Update": {
"TableName": "items",
"Key": {"id": {"S": itemId}},
"ConditionExpression": "available = :true",
"UpdateExpression": "set available = :false, " + "ownedBy = :player",
"ExpressionAttributeValues": {
":true": {"BOOL": True},
":false": {"BOOL": False},
":player": {"S": "playerId"},
},
},
},
{
"Update": {
"TableName": "players",
"Key": {"id": {"S": "playerId"}},
"ConditionExpression": "coins >= :price",
"UpdateExpression": "set coins = coins - :price, "
+ "inventory = list_append(inventory, :items)",
"ExpressionAttributeValues": {
":items": {"L": [{"S": itemId}]},
":price": {"N": str(itemPrice)},
},
},
},
],
)The two operations are completely isolated, there is no way to transfer data between them. All DynamoDB Transactions offers it that when one operation fails, both are rolled back.
Bad solution number 1: switch the order
Looking at the problem above, you might be tempted to switch the order of operations: first fetch the current LastID, then create the user with the fetched value + 1, then update the UserMetadata with the updated LastID. But this solution is guaranteed to lead to race conditions under load: when multiple users are added at the same time, they will get the same ID, even though the LastID will be updated twice. Additionally, if any of the operations fail, the database is left in an inconsistent state.
Bad solution number 2: create, then update the user
To work around this problem, you could first create the user with a placeholder LastID. If this operation is successful, update the UserMetadata with an atomic increment. Then update the user created before, setting its NumIdentifier to the atomically incremented value. There are multiple problems with this solution:
- If any operation fails, the data is left in an inconsistent state
- The user exists, but with an invalid NumIdentifier, between the PutItem and UpdateItem operations
- The solution is inefficient
Good solution: optimistic locking
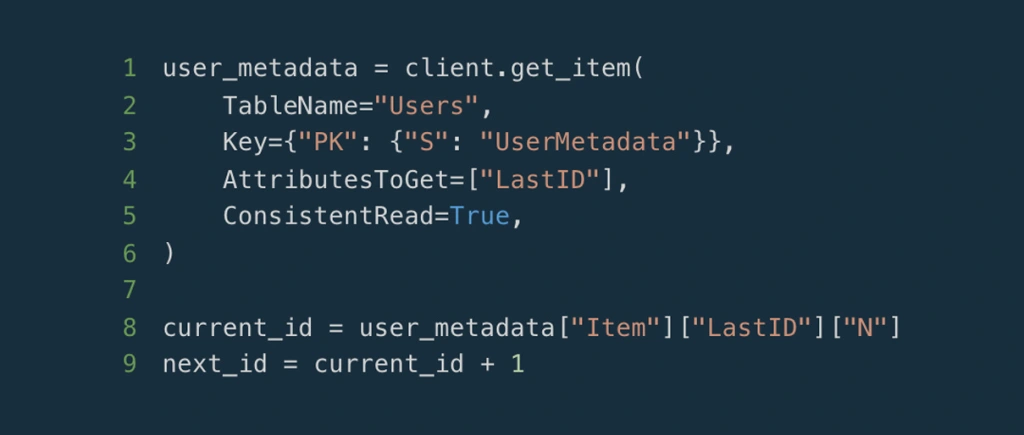
The right solution is to optimistically lock the ID, and verify the update in a transaction. Let’s begin by determining the NumericID you will probably use, by fetching the current ID and incrementing it in code.
user_metadata = client.get_item(
TableName="Users",
Key={"PK": {"S": "UserMetadata"}},
AttributesToGet=["LastID"],
ConsistentRead=True,
)
current_id = user_metadata["Item"]["LastID"]["N"]
next_id = current_id + 1Immediately after fetching the current_id we increment the UserMetadata and create the user in a transaction, while verifying that the metadata hasn’t been updated in the meantime.
client.transact_write_items(
TransactItems=[
{
"Update": {
"TableName": "Users",
"Key": {"PK": {"S": "UserMetadata"}},
"ConditionExpression": "LastID = :current_id",
"UpdateExpression": "SET LastID = LastID + :incr"
"ExpressionAttributeValues": {
":incr": {"N": 1},
":current_id": {"N": current_id},
},
},
},
{
"Put": {
"TableName": "Users",
"Item": {
"PK": {"S": "User#Kirk"},
"NumIdentifier": {"N": next_id},
"UserName": {"S": "Kirk"}
},
"ConditionExpression": "attribute_not_exists(PK)"
},
},
],
)If the operation fails with a ConditionalCheckFailed exception on the UpdateItem operation, we could retry the entire operation (fetching the LastID and the transaction) until it works. If the ConditionalCheckFailed exception occurs on the PutItem operation, we cancel the entire transaction and the auto-increment would retain its old value.
Conclusion
Generally speaking, auto-incrementing IDs in DynamoDB Tables are an anti-pattern. Most of the time, UUIDs or ULIDs are a better solution. However, real-world contexts sometimes introduce conflicting requirements, and storing auto-incrementing integers in DynamoDB might be the better tradeoff. The mechanism described in this article offers a reliable and efficient method to create unique, coherent, and automatically incrementing numeric IDs. Creating a new user requires one GetItem operation and one transaction consisting of an UpdateItem and a PutItem. Unless a conflict occurs, in which case the GetItem operation and the transaction are repeated until the conflict is resolved. This should not occur very often, unless you’re processing very high volumes of new users.
Attribution
This article was written as a result of a question I asked on Twitter. Uros Nikolic and Alex DeBrie explained the solution described in this post within 10 minutes of me asking the question. All credits for the concept go to them.
